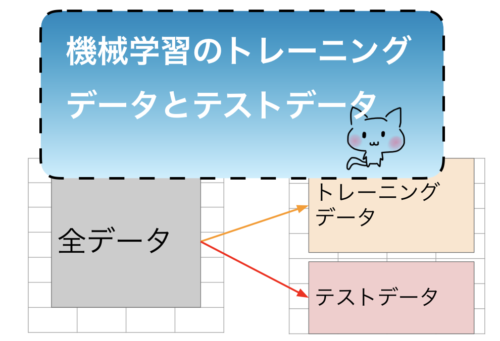
教師あり機械学習で使われるデータ
今回は、教師あり機械学習をもとに、使われるトレーニングとテストデータの違いを含めて勉強していきたいと思います!
学習の流れ
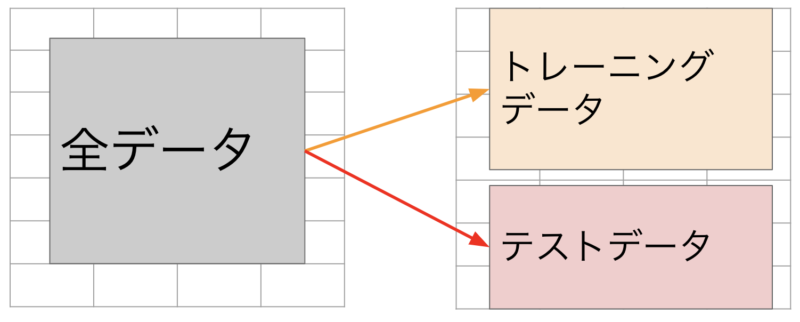
教師あり学習では、最初に全データをトレーニング(訓練)データセットとテストデータセットに分けます。
データの分割
一般的には、トレーニングデータとテストデータの分割比率は以下のような感じが多いようです。
またpythonのライブラリscikit-learnのデフォルト値では「75%と25%」で分類されます。
| トレーニングデータ(%) | テストデータ(%) |
|---|---|
| 80 | 20 |
| 75 | 25 |
| 70 | 30 |
分割後にトレーニングデータだけでモデルを学習し、テストデータでモデルの性能を評価します。
またデータの特性に偏りのあるトレーニングデータやテストデータを使って機械学習モデルを作成すると、精度の悪いモデルができてしまいます。
それを防ぐために、ランダムに並び替えたデータをトレーニングデータやテストデータにしたりします。
トレーニングデータ
訓練用データ、学習用データとも呼ばれます。
トレーニングデータを使って機械学習モデルの作成します。
機械学習モデルの作成は説明変数 (x) と目的変数 (y) の関係性を学習させます。
「目的変数」は求めたいもの、「説明変数」は目的変数に作用する変数です。
と言ってもピンとこないと思いますので、例えで説明します。
例えば、ある商品を売るとする場合、売上の予測をしたいと思いました。
その時に売上に関係する情報は温度、時期等が考えられます。
この場合、以下のような感じになります!
| 説明変数 (x) | 目的変数 (y) |
|---|---|
| 温度、時期 | 売上金額 |
簡単な機械学習のモデルでいうと、目的変数 (y) = a × 説明変数 (x) という数式関係が成り立つモデルを作成する感じですね!
テストデータ
テストデータは最終的な機械学習モデルの評価に使われます。
そのため、テストデータはモデルの学習や評価には使うべきではありません。
(過学習に繋がる可能性があるため)
過学習が何か不明な方は以下の記事をご参考ください (^ ^)
まとめ
今回は機械学習で用いるデータについて、勉強しました。
この流れを理解しないと教師あり機械学習の理解が難しいと思いますので、
少しでも理解できれば嬉しいです。
プログラミングを始めようと思った際は独学で勉強すると挫折する可能性が高いため、スクールも考えてもいいと思います!
おすすめはTechAcademy (テックアカデミー)のPythonコースやAIコースです!
初心者から始める TechAcademyの機械学習の基礎が学べる「Pythonコース」 ![]()
自宅で現役エンジニアから学べる TechAcademyのAI(人工知能)コース ![]()
