機械学習をする前に
機械学習では色々なデータから、予測や分類ができるようになります。
しかし、機会学習の前にデータに問題に問題があれば、どのような対応が必要なのでしょうか?
それが今回お話するデータの前処理が必要になります!
データ前処理の概要
簡単にいうと、データの前処理とは「綺麗なデータに加工する」という事です。
と言っても具体的なイメージがつかないと思いますので、詳細を説明します!
データ前処理のイメージ
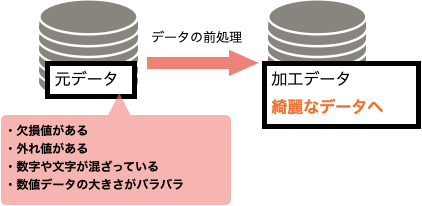
前処理は元データに以下のような事がある場合、正しく分析できなくなるため、必要になります。
- 欠損値がある
- 外れ値がある
- 数字や文字が混ざっている
- 数値データの大きさがバラバラである
データ前処理によって、機械学習の精度が高くできるって事です!
データ前処理でする事
では、実際にどんな事をしているか確認してみます。
以下のようなデータがあったとします。
このデータは前処理が必要なデータと言えるでしょうか?
| 個人No. | 個人名 | 誕生日 | 住所 | 身長 | 体重 | 収入 |
|---|---|---|---|---|---|---|
| 1 | XXX | 1988/5/2 | 東京都 | 180 | 79 | 1800 |
| 2 | YYY | 1966年7月11日 | 福岡県 | 158 | 60 | 450 |
| 3 | MMM | 2000/8/21 | NULL | 169 | 80 | 300 |
以下のデータには先ほど記載した正しく分析できなくなるデータが存在するため、前処理は必要です。
それではそれぞれのデータがどれにあたるかみてみましょう!
① 欠損値がある
今回は、個人No.3の「住所」のNULL(何もなし)が該当します。
② 外れ値がある
今回は個人No.1の「収入」の1800が該当します。
※今回は、日本人の平均収入からすると大きく外れているため。
③ 数字や文字が混ざっている
今回は、個人No.2の「誕生日」の1966年7月11日が該当します。
※他はYYYY/MM/DDの関係ですが、No.2のみ形式が違うため。
④ 数値データの大きさがバラバラである
今回は、身長と体重が収入にどのくらい影響を与えるかを分析すると仮定すると、体重と身長を同じ単位で扱う事はできません。
※この時に同じスケールで扱う際には標準化(平均を0に、標準偏差を1にする)という作業が必要になります。
標準化については以下の記事を参考にしてください(^ ^)
イメージは何となく、ついたでしょうか?
まとめ
今回は機械学習の中でも一番、時間がかかるデータの前処理についてでした。
機械学習はデータの前処理が最も大切だと言えるくらいに手間、時間がかかる部分です。
もっと機械学習について学びたいと思ったなら、プログラミングスクールとかも考えてもいいかもしれません。
それでは今日はここまで。
